La población es el conjunto completo de elementos objeto de nuestro estudio estadístico.
Cuando la población es muy numerosa o inaccesible, extraemos una muestra o subconjunto de la población. El número de elementos de la muestra n, se llama tamaño. Es muy importante para nuestro estudio que la muestra sea representativa de la población.
Un individuo es cada elemento de la población o de la muestra.
La Estadística es la Ciencia que recoge datos, los describe de manera útil y sencilla, los analiza y los interpreta con la ayuda de la Teoría de la Probabilidad.
Cuando analizamos datos, es posible usar una de las dos partes de la Estadística: Estadística descriptiva y Estadística inferencial.
La Estadística descriptiva recoge los datos, los organiza en tablas o gráficas y calcula los parámetros.
La Estadística inferencial saca conclusiones sobre los datos usando la Teoría de la Probabilidad.
La Estadística inferencial se divide en:
- Estadística inductiva, cuyo objetivo es estimar parámetros de la población bien usando un solo valor (estimación puntual) o bien usando un intervalo (estimación por intervalo).
- Estadística deductiva, que intenta comprobar que la información dada por la muestra coincide con las hipótesis estadísticas formuladas por el contraste de hipótesis.
En este tema vamos a ver estimación puntual. Para ello haremos una distinción entre los estadísticos de la muestra y los parámetros de la población:
- Los parámetros (de la población) son las medidas de centralización o de dispersión de la población: la media µ y la desviación típica σ.
- Los estadísticos (de la muestra) son las medidas de centralización o de dispersión de la muestra y dependen de la muestra. Usamos la media muestral, , y su desviación típica, S.
, y su desviación típica, S.
Para elegir las muestras, usamos el muestreo y sus diferentes tipos:

En una muestra aleatoria, cada individuo de la población tiene la misma probabilidad de ser elegido para la muestra.
Los diferentes tipos de muestreo aleatorio son:
–El muestreo aleatorio simple, m.a.s. (la base de los otros tipos) consiste en hacer una lista de los elementos de la población y elegir los n elementos de la muestra aleatoriamente.
–El muestreo aleatorio sistemático consiste en elegir los n elementos de la muestra de k en k donde:

–El muestreo aleatorio estratificado, también conocido como proporcional o quota, consiste en dividir la población en subgrupos homogéneos y coger una muestra aleatoria en cada subgrupo.
–El muestro aleatorio por conglomerados. El problema con los muestreos aleatorios aparece cuando tenemos una población diseminada por una ancha zona geográfica y tenemos que recoger los datos de los elementos que han salido en la muestra. En este tipo de muestreo, seguimos los siguientes pasos:
- Dividimos la población en conjuntos o conglomerados (normalmente en zonas geográficas cercanas)
- Hacemos una muestra simple de conglomerados
- Cogemos todos los elementos de esos conglomerados o una muestra aleatoria simple de sus elementos.
–Sin reemplazamiento:
–Error aleatorio muestral: para reducir este error hay que aumentar el tamaño de la muestra
–Error sistemático o sesgo está asociado al proceso de elección de la muestra y se reduce mejorando la selección de la misma
El estudio de las características de una población se hace mediante el estudio de algunas muestras. Los estadísticos de la muestra nos permiten decidir cuál es la mejor aproximación al parámetro de la población.
Para hacer esto, necesitamos saber la relación que hay entre los estadísticos de la muestra y los parámetros de la población. Como estos últimos se infieren de los estadísticos, necesitamos saber la distribución muestral de éstos.
Lo podemos hacer usando la:
- distribución muestral de las medias
De una población extraemos muestras de tamaño n, cada una con su propia media. Sea Xn la variable aleatoria que une cada muestra con su media. Podemos estudiar su distribución denominada distribución muestral de la media.
Cuando una población tiene cualquier distribución, usamos el:
Teorema central de límite. Si cogemos una muestra aleatoria simple de tamaño n de una variable aleatoria de media μ y desviación típica σ (n suficientemente grande, n ≥ 30), la distribución de probabilidad de la media Xn se aproxima a una distribución normal:
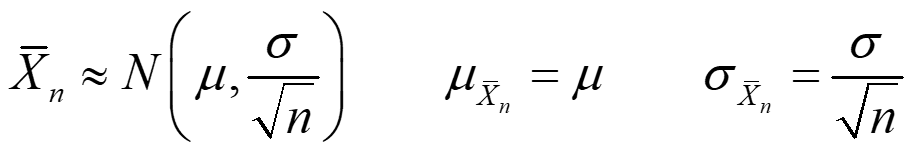
A σXn se le llama error típico.
Si tenemos una distribución normal N(μ,σ), entonces tenemos la misma situación:
Generalmente, la desviación típica de la población es desconocida. Entonces, aproximamos este parámetro usado la desviación típica de la muestra, si n es suficientemente grande (n ≥ 100).
- distribución muestral de las proporciones
Cuando en una población procedemos a estudiar una característica con sólo dos posibles valores (éxito/fracaso), entonces la población sigue una distribución binomial.
Cada muestra de la población tiene un porcentaje de individuos que tiene esta característica. p es la proporción de éxito de esta variable aleatoria de la población. La proporción de fracaso es q = 1 – p
Sean todas las muestras de tamaño n de la población. Cada muestra tiene una proporción de individuos con esa característica.
La distribución asociada a la variable aleatoria que une cada muestra con su proporción se llama distribución muestral de proporciones.
Como, para poblaciones grandes, la binomial se aproxima a la normal, la distribución muestral de proporciones también sigue una distribución normal:
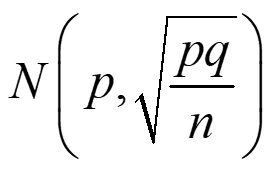
si n es suficientemente grande, n ≥ 30, and np ≥ 5, nq ≥ 5
Como generalmente las proporciones de la población son desconocidas, las aproximamos por las de la muestra.